Software-Prozeßmodellierung und -Durchführung
Schwierigkeiten des Technologietransfers
| Volker Gruhn | Juri Urbainczyk |
| University of Dortmund | o.tel.o |
| Computer Science | Universitätsstraße 140 |
| 44221 Dortmund | 44799 Bochum |
| Germany | Germany |
| ++ 49 (0) 231 755 2782 | ++49 (0) 69 7896 0145 |
Zusammenfassung:
In diesem Artikel diskutieren wir, inwiefern die Forschung auf dem Gebiet der Software-Prozeßmodellierung und rechnergestützten Durchführung von Software-Prozessen Einfluß auf die industrielle Praxis der Software-Entwicklung hatte und hat. Wir unterscheiden dabei verschiedene Phasen: von anfänglicher Euphorie über vollständige Desillusionierung bis hin zur Anwendung von Prozeßtechnologie auf Geschäftsprozesse und schließlich bis zur beispielhaften Anwendung von Prozeßmodellierung und rechnergestützter Durchführung auf bestimmte Teile von Software-Prozessen. Wir diskutieren ein Beispiel der Anwendung von Software-Prozeß-Technologie auf einen Fehlerverfolgungsprozeß in der industriellen Praxis. Abschließend erörtern wir, wie die Forschung in Modellierung und rechnergestützter Durchführung von Software-Prozessen fokussiert werden könnte, um schneller zu in der Praxis nutzbaren Ergebnissen zu führen.
Schlüsselwörter:
Software-Prozeßmodellierung, rechnergestützte Durchführung von Software-Prozessen, Workflow-Management, FUNSOFT-Netze
1 Status der Forschung im Bereich der Software-Prozeß-Technologie
In der akademischen Software-Technologie-Forschung hat sich seit gut zehn Jahren das Gebiet der Software-Prozeßmodellierung und der rechnergestützten Durchführung von Software-Prozessen als Forschungszweig etabliert. Es gibt regelmäßige European Workshops on Software Process Technology [23], International Software Process Workshops [11] und eine Reihe von International Conferences on the Software Process [21]. Die meisten Software-Engineering-Konferenzen umfassen eine oder mehrere Sitzungen, die sich mit Software-Prozeß-Themen beschäftigen [3,1].
Der Fokus dieser hauptsächlich akademisch ausgerichteten Forschungsarbeit hat sich im Laufe der Jahre gewandelt. Die späten 80er Jahre waren von der Frage geprägt, ob Software-Prozeßmodelle wie Programme behandelt werden sollten [22] oder ob Software-Prozesse zu sehr von menschlicher Interaktion und Kreativität geprägt sind als daß das möglich wäre [20]. Ohne, daß bezüglich dieser Frage ein Konsens erzielt worden wäre, waren die frühen 90er durch heftige Diskussionen bezüglich der Frage bestimmt, welchem Sprachparadigma eine Software-Prozeßmodellierungssprache folgen sollte. Die prominentesten Vertreter solcher Sprachen umfassen regelbasierte Sprachen, Petri-Netz-basierte Sprachen und objektorientierte Sprachen [1,2,4,17].
Gleichermaßen zeigen die letzten Jahre einen neuen Trend: es wird akzeptiert, daß verschiedene Prozeßmodellierungssprachen ihre Berechtigung haben und es gibt einen wachsenden Konsens, daß graphische Sprachen helfen, um Prozeßmodellierung auch für Nichtexperten zu ermöglichen. Gleichzeitig ist ein Forschungsschwerpunkt im Bereich der Software-Prozeßevolution entstanden. Unter Prozeßevolution wird verstanden, daß Software-Prozeßmodelle geändert werden während sie als Grundlage der rechnergestützten Durchführung von Software-Prozessen verwendet werden. Die Notwendigkeit ist schon vor Jahren erkannt worden [5,2]. Mittlerweile wird allgemein akzeptiert, daß Software-Prozesse komplexe Entitäten sind, die inhärent auf permanenter Änderung und Fortentwicklung basieren. Das bedeutet, daß die Evolution von Prozeßmodellen nicht auf Modellierungs- oder Planungsfehler zurückzuführen ist, sondern auf die Tatsache, daß Software-Prozesse in stetiger Wechselwirkung mit ihrer Umgebung stehen und daß diese zu Prozeßmodelländerungen führt.
Parallel zu diesen Änderungen in der Hauptausrichtung der Software-Prozeß-Forschung, haben viele Forschungsgruppen weltweit Prototypen von Werkzeugen zur Software-Prozeßmodellierung, zur Analyse von Software-Prozeßmodellen und zur rechnergestützten Durchführung von Software-Prozessen entwickelt. Zu ihnen zählen unter anderem:
Neben diesen Prototypen gibt es eine Reihe von Ansätzen, die noch nicht durch Werkzeuge unterstützt werden, die aber der Dynamik von Software-Prozessen durch geeignete Modellierungsmittel Rechnung tragen (Dynamite [15], SOCCA [4]).
Trotz dieser Vielfalt von Prototypen und Konzepten ist es bisher nur zu experimentellen Anwendungen von Software-Prozeßmodellierung und rechnergestützter Durchführungsunterstützung auf industrielle Software-Prozesse gekommen. Erfahrungen bei der Durchführung solcher Experimente werden beispielsweise in [9], [4] und [14] beschrieben.
2 Software-Prozeß-Technologie in der Praxis: Erfahrungen
In diesem Abschnitt beschreiben wir einige Erfahrungen bei dem Versuch, Ergebnisse der Software-Prozeß-Forschung in die industrielle Software-Entwicklung zu transferieren. Diese Erfahrungen beruhen auf dem Transfer von MELMAC und MELMAC-Konzepten.
2.1 Phase 1: Enthusiasmus
Das Prozeß-Management-Werkzeug MELMAC ist Ende der 80er Jahre im akademischen Kontext entstanden. Die Entwickler waren zutiefst davon überzeugt, daß die industrielle Software-Entwicklung händeringend auf Software-Prozeß-Management im allgemeinen und MELMAC im besonderen warten würde.
Leider stellte sich bei Versuchen der Anwendung von MELMAC auf industrielle Software-Prozesse heraus, daß MELMAC zwar tragfähige Konzepte verwirklichte, aber weder stabil noch ausreichend dokumentiert war. Zudem war die Handhabung von MELMAC gewöhnungsbedürftig und entsprach nicht den gängigen Anforderungen an Benutzungsoberflächen. Unabhängig von diesen konkreten Hindernissen bei der Anwendung eines konkreten Werkzeuges, ließen die genannten Bemühungen allgemeine Zweifel an der Relevanz des Software-Prozeß-Managements aufkommen. Während die Software-Prozeß-Forschergemeinde in der Terminologie von Prozessen, Objektmodellen, Prozeßmodellierungssprachen, und präskriptiven und deskriptiven Modellierungssprachen miteinander diskutierte, sprachen industrielle Softwareentwickler über Programmiersprachen, Budgetüberschreitungen, Fehlerbeseitigungen und Transaktionsmonitore. Die Schnittmengen zwischen beiden Terminologien war nahezu leer, so daß es relativ schwierig und langwierig war, eine einheitliche Kommunikationsgrundlage zu schaffen. Auf der Basis dieser Grundlage stellte sich dann heraus, daß die allgemeinen Prozeßverbesserungsansprüche des Prozeß-Managements weit von der täglichen Praxis der Software-Entwicklung entfernt waren. Diese bedurfte konkreter Verbesserungen des Konfigurations-Managements, des systematischen Tests, der Abstimmung zwischen Vertriebsleuten und Entwicklern oder auch der Änderungskontrolle für einen Softwareentwurf. Diese konkreten Probleme erforderten zunächst nicht primär rechnergergestützte Durchführung, sondern erst einmal eine klare Organisation des Software-Prozesses. Insofern war es nützlich, Software-Prozesse zu modellieren. Die Anforderungen an die reine Modellierung wurden jedoch von den zur Verfügung stehenden Werkzeugen und Modellierungssprachen nur ungenügend erfüllt. Statt der klaren Darstellung der verschiedenen Aspekte von Software-Prozessen (organisatorischer Kontext, Struktur von Dokumenten, Abläufe, Berechtigungen beteiligter Personen) war die Software-Prozeßmodellierung sehr stark auf die Ausführbarkeit der Prozeßmodelle ausgerichtet. Auf diese Weise konnten zwar alle Facetten von edit-compile-test-Zyklen [6] beschrieben werden, aber der organisatorische Gesamtzusammenhang der Software-Entwicklung blieb zumeist unbeachtet. Abgesehen davon stellte sich die Vielfalt der Ausnahmen in den industriellen Prozessen als ein Hindernis für die Anwendung der Prozeßmodellierung heraus. Gemäß des Capability Maturity Models [19] waren die meisten der untersuchten Prozesse zwischen Stufe 1 (initial) und Stufe 2 (wiederholbar). Das bedeutet, sie waren in weiten Teilen unklar und die Zusammenhänge zwischen den Aktivitäten waren nicht allen beteiligten Personen klar. Anders ausgedrückt: die prozeßorientierte Sicht auf die Software-Entwicklung war wenig ausgeprägt. In dieser Weise wirkten die ganz konkreten Probleme und der niedrige Reifegrad der Software-Entwicklung nahezu prohibitiv auf die Anwendung des Prozeß-Managements, das keinen kurzfristigen return-on-investment versprach.
2.3 Phase 3: Trost
Nachdem erst einmal unverkennbar war, daß Software-Prozeß-Management kaum auf reale Software-Prozesse anwendbar war, ergab sich die Gelegenheit, die Geschäftsprozesse, die durch ein neu zu entwickelndes Softwaresystem unterstützt werden sollten, zu untersuchen. Bei dem neuen Softwaresystem handelt es sich um das wohnungswirtschaftliche Informationssystem WIS, das von LION (zwischenzeitlich: Vebacom Service, heute: o.tel.o) im Auftrag eines Konsortiums von acht Kunden entwickelt worden ist. Beispiele für die Geschäftsprozesse, die durch WIS unterstützt werden, sind:
WIS wurde vollständig prozeßorientiert entwickelt. Das bedeutet, daß die zu unterstützenden Geschäftsprozesse zunächst modelliert wurden (Abläufe mit FUNSOFT-Netzen, zugrundeliegende Daten mit Hilfe von erweiterten Entity-Relationship-Modellen [13] und der organisatorische Kontext mit Hilfe von Organigrammen und Berechtigungen), dann analysiert wurden und letztlich auf der Basis eines Workflow-Management-Systems durchgeführt wurden.
Die Gründe für die prozeßorientierte Entwicklung waren:
Ausgehend von diesen Gründen wurden verschiedene Werkzeuge, die die prozeßorientierte Entwicklung unterstützen, untersucht. Bei dieser Untersuchung wurden sowohl reine Prozeßmalwerkzeuge einbezogen (also solche, die bunte Bilder liefern und den Ersteller aus der Pflicht entlassen, sich über die Bedeutung dieser Bilder allzu viele Gedanken zu machen) als auch traditionelle Workflow-Management-Systeme, die die Programmierung von Prozeßmodellen mit recht proprietären Sprachen unterstützen. Eine dritte untersuchte Werkzeugklasse bildete kombinierte Workflow-Management- und Entwicklungswerkzeuge, die fast immer auf der Generierung von Programmcode aus graphisch beschriebenen Prozeßmodellen beruhen. Als Ergebnis dieser Untersuchung wurde 1992 entschieden, die Workflow-Management-Umgebung LEU [8] zu entwickeln. LEU basiert auf den Konzepten des Prototypen MELMAC und setzt diese vollständig um.
Wesentliche Idee von LEU ist es, genau eine Repräsentation der zu unterstützenden Prozeßmodelle zu verwenden. Prozesse werden modelliert, Prozeßmodelle werden analysiert und schrittweise realisiert und die realisierten Prozeßmodelle werden durch die Workflow-Engine [16] zur Laufzeit zur Durchführung gebracht [12]. LEU wurde als einziges Entwicklungswerkzeug für WIS eingesetzt und steuert heute die Geschäftsprozesse mehrerer großer Wohnungsunternehmen.
2.4 Phase 4: Neue Erkenntnis
Die zeitgleiche Einführung von WIS bei mehreren Kunden hat zu der Identifikation vieler Fehler in WIS geführt. Die Gleichzeitigkeit der Einführung hat zudem bewirkt, daß derselbe Fehler von verschiedenen Seiten gemeldet wurde. Abgesehen von Fehlern wurden zahlreiche neue Anforderungen offensichtlich, die zu großen Teilen kundenseitig ebenfalls als Fehler gemeldet wurden.
Um diese Flut von Fehlern und Anforderungen zu bewältigen (teilweise bis zu 50 pro Tag), mußten alle eingehenden Meldungen klassifiziert, elektronisch erfaßt und beantwortet werden. Eine Antwort konnte dabei so aussehen, daß die Berücksichtigung einer Anforderung für ein zukünftiges WIS-Release angekündigt wurde oder daß für einen Fehler ein Beseitigungszeitpunkt oder ein Workaround (also eine behelfsmäßige Vermeidungsstrategie) genannt wurde. Für jeden Fehler mit hohem Schadenspotential mußten darüber hinaus alle WIS-Anwender umgehend benachrichtigt werden.
Dieser Fehlerverfolgungsprozeß wurde mit LEU realisiert. Diese Vorgehensweise paßt zu den Ergebnissen aus [24]. Hier wird geschildert, daß Softwareentwickler am ehesten dazu neigen, den Bereich der Fehlerverfolgung zu automatisieren. Der Umweg über WIS hat auf diese Weise dazu geführt, daß zumindest Teile eines Software-Prozesses mit den Mitteln der Software-Prozeß-Technologie unterstützt wurden. In den folgenden Abschnitten wird dieser Software-Prozeßteil und seine Durchführung detailliert diskutiert.
3 Das PTS-Beispiel
Die Kundeneinführung und Wartung des Softwaresystems WIS verlangt nach einer professionellen Unterstützung durch entsprechende Software, wie ein Helpdesk mit umfangreicher Fehlerdatenbank. Die Aufgabengebiete dieser Software liegen vor allem in der Unterstützung und Durchführung der Prozesse Problemverfolgung, Anforderungsmanagement und Software-Konfigurationsmanagement. Diese Prozesse sind stark arbeitsteilig und haben eine extrem hohe Wiederholungszahl. Darüber hinaus sind sie gut dokumentiert und definiert, da mit der Einführung eines Qualitätsmanagement-System (QMS) bei o.tel.o-Bochum zur ISO-9000-Zertifizierung alle hausinternen Geschäftsprozesse (GP) untersucht und beschrieben worden sind. Aufgrund dieser Voraussetzungen wurde beschlossen ein geschäftsprozeß-basiertes Problem Tracking System (PTS) mit LEU zu entwickeln.
Folgende Hauptanforderungen werden an das System gestellt:
Die Einführung einer software-gestützten und geschäftsprozeß-orientierten Problemverfolgung soll den Weg des Problemreports nachvollziehbar machen. Informationen über die bearbeiteten Probleme müssen jederzeit und von jedem abrufbar sein. Auf diesem Wege kann dann z.B. schnell erkannt werden, ob ein Problem bereits aufgenommen oder sogar gelöst wurde. Auch können dadurch Kundenanfragen bezüglich Bearbeitungsstatus und -dauer schneller beantwortet werden. Der Aufwand und die Fehleranfälligkeit beim Erfassen eines Problemreports soll wesentlich gesenkt und die Gesamtbearbeitungszeit für einen Problemreport verkürzt werden. Verschiedene Tätigkeiten wie z.B. das Schreiben von Kundenbriefen können automatisiert und Controlling-Möglichkeiten geschaffen werden. Die Fehleranfälligkeit des Problemverfolgungsprozesses selbst soll durch Konsistenzsicherungsmaßnahmen, die schon in den Dialogen greifen und die z.B. ein Eintragen von falschen Werten verhindern, verringert werden. Jeder Mitarbeiter soll an seinem Arbeitsplatz in einer Agenda nur die Aktivitäten zur Ausführung angeboten bekommen, die ihm laut QMS-Verfahren zustehen.
Die Modellierung eines LEU-Projektes setzt sich aus Objektmodell, Organisationsmodell und Ablaufmodellen zusammen. Diese Bestandteile des PTS werden nachfolgend vorgestellt.
3.1 Objektmodell
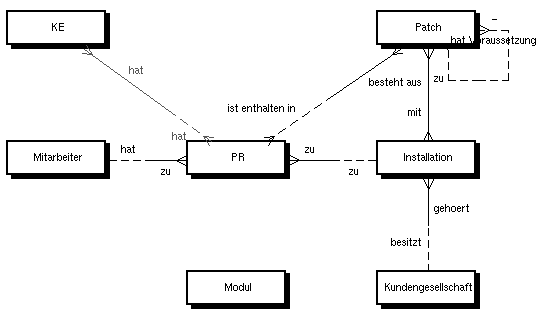
Die Modellierung in LEU erfolgt in einer erweiterten Entity-Relationship-Darstellung. Die zentralen Objekttypen des PTS sind Problemreports (PR), Konfigurationseinheiten (KE) und Patches. Sie sind durch n:m-Verbindungen miteinander verknüpft (Abbildung 1: Objektmodell des PTS). Darüber hinaus gibt es Objekttypen zur Verwaltung der Stammdaten des Problem Tracking Systems, wie z.B. Modul und Mitarbeiter.
In den Objekten des Objekttypen Problemreport werden alle eingehenden Problemmeldungen erfaßt. Durch das Boolean-Attribut Intern unterscheiden wir dabei zwischen
Jeder Problem Report erhält einen eindeutigen Schlüssel, der im Attribut Problemnummer abgelegt wird. Der Inhalt der Problemmeldung wird in den Attributen Problembeschreibung, Fehlercode, Kurzbeschreibung und Auswirkungen des Problems dokumentiert. Ebenso wird der Auftraggeber und ein Ansprechpartner sowie dessen Telefonnummer festgehalten. Zu jedem Problem wird vermerkt, auf welcher Installation welches Kunden, mit welchem Release und in welchem Softwarebestandteil es aufgetreten ist. Die möglichen Werte dieser Attribute werden vor der Inbetriebnahme des PTS festgelegt. Auf diese Weise wird sichergestellt, daß beim Arbeiten mit dem PTS z.B. nur zugelassene Installationen gültiger Kunden eingegeben werden können. Desweiteren hat jeder Problemreport einen aktuellen Bearbeiter, der zudem historisiert wird. Das bedeutet, daß sowohl der Name des jeweiligen Bearbeiters als auch Zeitpunkt und Status des Problemreports in einer Liste festgehalten werden. Diese Liste stellt dann die gesamte Bearbeitungshistorie des Problemreports dar und kann jederzeit eingesehen werden, um z.B. Eskalationsmechanismen anzustoßen. Der Zustand eines Problemreports wird durch die Attribute Status und Ergebnis dokumentiert. Status beschreibt, welcher Arbeitsschritt zur Zeit an diesem Problemreport durchgeführt wird. Ergebnis wird erst beim Abschluß eines Problemreports von ‘Offen’ auf entweder ‘Behoben’, ‘Anwender-Fehler’ oder ‘Nicht reproduzierbar’ gesetzt. Nicht alle eingehenden Probleme sind auch solche. Stellt sich z.B. während der Bearbeitung heraus, daß es sich in Wirklichkeit um einen Änderungswunsch handelt, so wird dies mit dem Boolean-Attribut Anforderung dokumentiert. So können auch Anforderungen mit dem PTS verwaltet werden
.
Abbildung 1: Objektmodell des PTS
Gemäß der n:m-Verbindung in der Entity-Relationship-Darstellung können einem Problemreport eine oder mehrere Konfigurationseinheiten zugewiesen werden. Eine Konfigurationseinheit kann andersherum auch mehreren Problemreports zugeordnet sein, muß aber mindestens zu einem PR gehören. Konfigurationseinheiten entstehen, wenn im Zuge der Bearbeitung eines Problems von der Entwicklung Änderungen am bestehenden Softwaresystem durchgeführt werden müssen. Der Objekttyp Konfigurationseinheit enthält fünf Attribute: Typ, Komponente, Name, Version und Installationsanweisung. Typ gibt an, ob es sich z.B. um eine Bibliothek, ein ausführbares Programm oder ein Oberflächenskript handelt. Die Komponente verweist auf einen Softwarebestandteil bzw. auf ein Modul. Der Name enthält den tatsächlichen Bezeichner der Konfigurationseinheit, die Version beinhaltet die Major- und Minor-Releasenummer. Das Attribut Installationsanweisung enthält zusätzliche Informationen, die zur Inbetriebnahme dieser Konfigurationseinheit notwendig sind und die der Konfigurationsmanager (KM) in die Patchanweisung aufnimmt.
Über eine weitere n:m-Verbindung lassen sich Mengen von Problemreports zu Patches zusammenfassen. Jeder Patch muß immer mindestens einen zugeordneten Problemreport besitzen. Da auch eine Verbindung von Problemreport zu Konfigurationseinheit besteht, läßt der Patch sich so auf seine Konfigurationseinheiten zurückführen. Zusätzlich enthält der Objekttyp Patch Attribute zur Erfassung von Produktbezeichnung, Release, Patchlevelnummer und Variante (z.B. Solaris/Oracle).
3.2 Organisation
An den mit dem PTS durchgeführten Prozessen sind fünf Personengruppen beteiligt: die Supportabteilung, das Patchboard, die Entwicklungsabteilung, die Qualitätssicherung und die Konfigurationsmanager. In den durch das PTS abgedeckten Geschäftsprozessen kommen diesen fünf Gruppen folgende Aufgaben zu:
Alle Aktivitäten in den Ablaufmodellen lassen sich eindeutig einer der fünf beteiligten Gruppen zuweisen, wobei das PTS jeweils nur die Aktionen zuläßt, die den jeweiligen Aufgaben der Personengruppe entsprechen.
3.3 Ablaufmodelle
Das jeweilige Ablaufmodell bestimmt die möglichen Wege, die ein PR durch den Geschäftsprozeß nehmen kann. Welcher Pfad allerdings im konkreten Fall eingeschlagen wird, hängt in großem Maße von dem Attribut Status des PR ab, welches in Interaktion mit dem Benutzer geändert werden kann. Befindet sich ein PR in einem bestimmten Status, so sind jeweils nur bestimmte Änderungen dieses Attributes erlaubt (Abbildung 2: Zustandsübergangsdiagramm für PR). Bleibt das Attribut Status unverändert, können Aktivitäten zyklisch beliebig oft mit dem gleichen PR durchlaufen werden. Zur vollständigen Dokumentation des PTS ist diese Art der Beschreibung unbedingt erforderlich. Die Durchführung der Prozesse beruht jedoch allein auf den Ablaufmodellen.
Durch das Problem Tracking System werden grundsätzlich zwei Geschäftsprozesse, nämlich Abnahme und Wartung, unterstützt. Zusätzlich gibt es ein Ablaufmodell, das für die automatische Überleitung von per eintreffenden Problemmeldungen zuständig ist, und das keine Benutzerdialoge beinhaltet.
Der Abnahmeprozeß (Abbildung 3: Ablaufmodell ‘Abnahme’) wird durchlaufen, sobald ein neues Release für eine Softwaresystem von der QS abgenommen werden soll. Nach einer Entwicklungsphase wird der aktuelle Entwicklungsstand des Produkts gegen die Anforderungsdokumentation geprüft und gefundene Fehler in Problemreports festgehalten. Diese gehen an die Entwicklung, welche die Fehler beseitigt. Die QS wiederum muß die Korrektur verifizieren. Dieser Zyklus kann beliebig oft wiederholt werden, bis die QS das Softwaresystem freigibt.
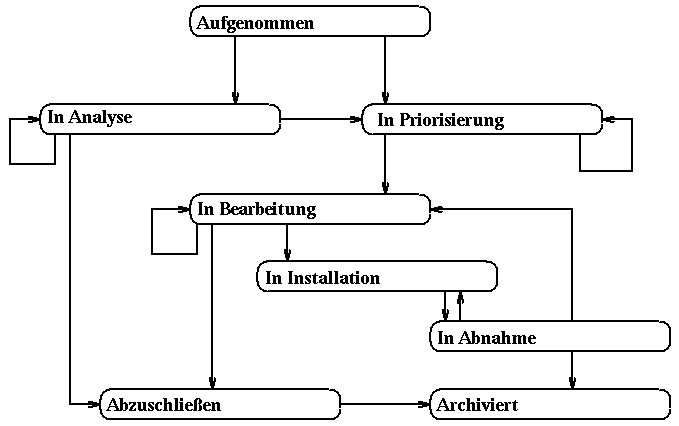
Abbildung 2: Zustandsübergangsdiagramm für PR
Der Wartungsprozeß (Abbildung 4: Ablaufmodell ‘Wartung’) wird durchlaufen, wenn Fehler in einem bestehenden, bereits freigegebenen Softwaresystem gefunden werden. Diese Fehler können sowohl von Kunden als auch hausintern gemeldet werden und führen nach ihrer Behebung zu Patches für das Softwaresystem. Die Patches wiederum werden von der QS abgenommen, wobei mehrere Zyklen durchlaufen werden können.
Ablaufmodelle werden mit FUNSOFT-Netzen beschrieben [6]. Sie bestehen aus Instanzen und Kanälen. Instanzen repräsentieren Aktivitäten. Diese Aktivitäten erfordern teilweise manuelles Eingreifen der Prozeßbeteiligten (sie werden dann Dialogaktivitäten genannt) und können teilweise automatisch durchgeführt werden (sie werden dann Batchaktivitäten genannt). Kanäle repräsentieren Informationsspeicher. Sie können Objekte enthalten (in Petrinetz-Terminologie: sie sind markiert). Instanzen werden graphisch durch verschiedene rechteckige Symbole dargestellt. Die verschiedenen Symbole dienen zur Veranschaulichung und haben keine Semantik. Kanäle werden graphisch durch Kreise dargestellt. Eine Kante von einem Kanal zu einer Instanz bedeutet, daß die Instanz beim Beginn ihrer Ausführung ein Objekt aus dem Kanal liest. Eine Kante von einer Instanz zu einem Kanal bedeutet, daß die Instanz am Ende ihrer Ausführung ein Objekt in den Kanal schreibt. In FUNSOFT-Netze gibt es einige Modellierungskonstrukte, die die dichte Beschreibung von Abläufen ermöglichen. So gibt es beispielsweise eine Reihe vordefinierter Schaltverhalten. Ein solches Schaltverhalten ist das entweder-oder-Schaltverhalten, mit Hilfe dessen es möglich ist, zu beschreiben, daß eine Instanz in genau einen ihrer Ausgangkanäle schreibt. Andere FUNSOFT-Netz-Konstrukte (wie der Parallelitätsgrad einer Instanz und die Art des Zugriffes auf einen Kanal) dienen in ähnlicher Weise der intuitiv zugänglichen Beschreibung von Abläufen. Die Semantik dieser Konstrukte ist durch eine Abbildung auf Prädikat/Transitions-Netze definiert [10].
Abnahme
Der Abnahmeprozeß enthält sechs Aktivitäten, wobei vier Aktivitäten zyklisch durchlaufen werden können. Zwischen den Aktivitäten liegt jeweils ein Kanal, der Token vom Typ Problemreport enthalten kann. Alle Aktivitäten sind manuelle Dialoginstanzen, das heißt sie müssen von einem Mitarbeiter per Hand aus seiner Agenda gestartet werden und führen zur Bearbeitung einer Dialogmaske. Die Aktivität ‘PR Erstellen’ muß immer in der Agenda stehen, da die QS jederzeit die Möglichkeit haben muß, einen Problemreport zu erfassen. Das wird technisch durch einen Control-Kanal im Vorbereich erreicht, von der eine Copy-Kante zur Aktivität führt. Die gleiche Modellierungstechnik wird auch für PR Einsehen und PR Ändern verwendet, die ebenfalls immer in der Agenda stehen müssen. Alle weiteren Instanzen können erst dann schalten, wenn ein Token vom Typ Problemreport im Vorbereich liegt und erscheinen auch erst dann in der Agenda.
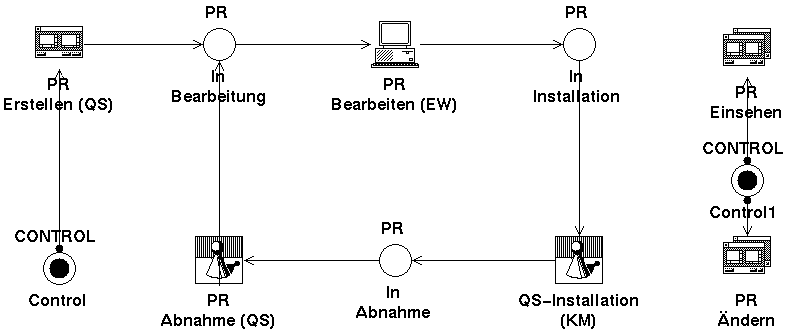
Abbildung 3: Ablaufmodell ‘Abnahme’
Über eine OUT-Kante ist die letzte Aktivität ‘PR Abnahme’ wieder mit dem Kanal verbunden, der im Vorbereich der Instanz ‘PR Bearbeiten’ steht. Dadurch kann ein nicht behobener Fehler wieder in die Entwicklung zurückgeführt werden.
Die Aktivität PR Einsehen darf von jedem Benutzer ausgeführt werden. In dieser Dialoginstanz kann jeder Problem Report, der in diesem GP angelegt wurde, im Read-Only-Modus gesucht und angesehen werden. PR Ändern darf nur von ausgesuchten Benutzern (z.B. einem Systembetreuer) ausgeführt werden. Das Berechtigungssystem von LEU erlaubt es, entsprechende Rollen zu definieren und diese Rollen den jeweiligen Benutzern zuzuordnen. Die Rolle RoleEditPR, welche die Berechtigung zum Starten von PR Ändern enthält, wird also nur mit ausgesuchten Benutzern verknüpft. Die Aktivitäten PR Erstellen und PR Abnahme dürfen nur von Benutzern aufgerufen werden, denen die Rolle QS zugeordnet wurde. PR Bearbeiten steht nur in der Agenda der Benutzer, die eine Entwickler-Rolle besitzen. QS-Installation ist für Mitarbeiter mit der Rolle Konfigurationsmanager reserviert.
Wartung
Der Wartungsprozeß beschäftigt sich mit externen Problemreports. Bei der Behebung dieser von Kunden gemeldeten Fehler entstehen Patches, so daß hier nicht nur Kanäle vom Typ Problemreport sondern auch vom Typ Patch existieren. Alle Aktivitäten bis auf Kunden Informieren sind manuelle Dialoginstanzen. Sechs Zyklen erlauben es, verschiedene Phasen des Prozesses beliebig oft zu durchlaufen. Die Aktivitäten PR Analysieren, PR Bearbeiten und PR Priorisieren können wahlweise (je nach Status des PR) auch wieder ein Token in den Vorbereich zurückschreiben, da sie mit ein und demselben Dokument beliebig oft hintereinander ausgeführt werden können.
Der Kanal ‘In Analyse’ ist ein Systemkanal.. In LEU dienen Systemkanäle zum Austausch von Daten auch über Geschäftsprozeß-Grenzen hinweg. Hier hat er die Funktion, per Email eintreffende PR direkt in den Wartungsprozeß hineinzubringen. Dieser Systemkanal kann also nicht nur durch die Aktivität PR Erstellen gefüllt werden, sondern auch durch eine automatische Aktivität im Mail-Batch.
Der Mail-Batch
Das Mail-Ablaufmodell dient zum automatischen Erfassen von Problem Reports aus eingehenden Emails. Er wird einmal gestartet und läuft dann solange, bis das PTS heruntergefahren wird. Da seine einzige Aktivität nach dem Terminieren ein Control-Token in den Vorbereich zurückschreibt, wird sie immer wieder von neuem angestoßen. Die Aktivität liest das Mailfile eines bestimmten UNIX-Benutzers und durchsucht die Emails nach definierten Schlüsselworten, wie z.B. ‘#PROBLEMBSCHREIBUNG:’ Hieraus wird ein Problem Report erstellt. Dieser PR hat den Status ‘In Analyse’ und als Bearbeiter wird immer die Gruppe Support eingetragen. Der Problemreport wird anschließend in den Systemkanal im Nachbereich der Aktivität geschrieben. Der gleiche Systemkanal liegt im Wartungsprozeß im Vorbereich der Aktivität PR Analysieren und sorgt so dafür, daß die eingehenden PR gleich in den Geschäftsprozeß einfließen. Auf diese Weise können per Email Problembeschreibungen direkt in das PTS eingespielt werden. Da Emails auch dann empfangen werden, wenn das System nicht in Betrieb ist, können keine Nachrichten verloren gehen. Dieser Mechanismus ist eine ideale Schnittstelle für Kunden oder Mitarbeiter, die sich beim Kunden befinden, und die nicht direkt eine Agenda zur Verfügung haben.
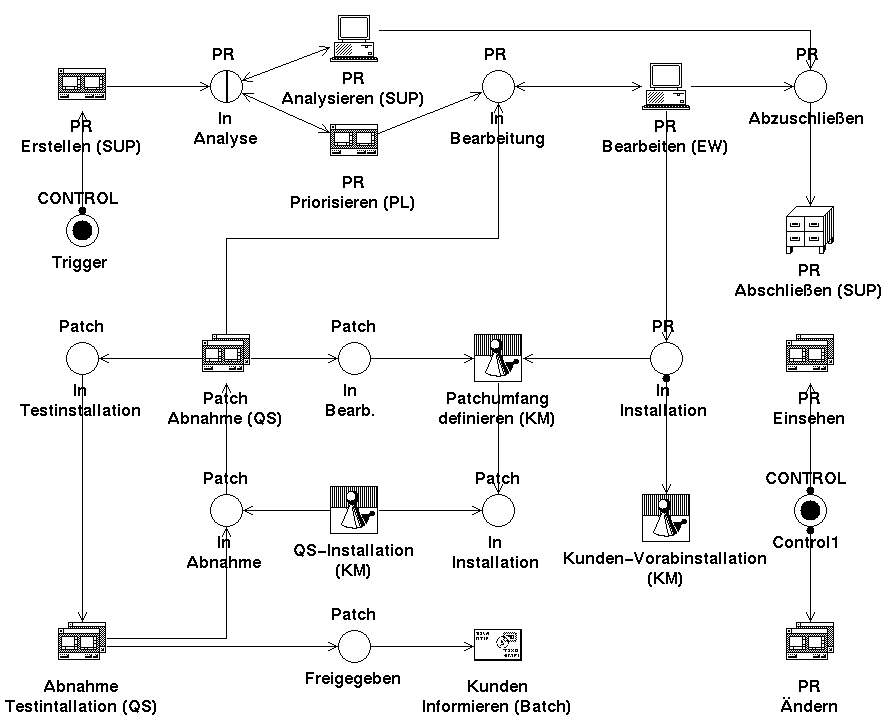
Abbildung 4: Ablaufmodell ‘Wartung’
Darüber hinaus wird so auch eine HTML-Schnittstelle zur Verfügung gestellt. Die abgebildete HTML-Seite (Abbildung 5: PTS HTML-Seite) steht sowohl hausintern per Intranet als auch extern im WWW zur Verfügung. Das auf dieser Seite eingerichtete HTML-Formular ermöglicht die Eingabe aller relevanten Attribute, die zum Anlegen eines PR notwendig sind. Einige Attribute, wie z.B. Kunde, sind nur per Auswahlliste einzugeben, um Fehler beim automatischen Einlesen des PR zu verringern. Bei Betätigung des Buttons ‘Abschicken’ wird das Formular ausgelesen und per CGI-Schnittstelle ein Hilfsprogramm aufgerufen, das aus den Daten des Formulars eine Email mit entsprechenden Schlüsselwörtern erzeugt. Falls nicht genügend Daten für einen sinnvollen PR vorliegen (wenn z.B. die Problembeschreibung fehlt), wird die Generierung der Email mit einem Fehler abgebrochen. Sind jedoch alle Informationen vorhanden, wird die Email an genau die Adresse versandt, welche vom Mail-Batch des PTS ausgelesen wird. Auf diese Weise reicht eine Schnittstelle des PTS aus, um zwei weitere Medien zum Erfassen von PR zur Verfügung zu stellen.
4 Arbeiten mit PTS
Um die Art und Weise des tagtäglichen Einsatzes des PTS darzustellen, soll an dieser Stelle exemplarisch ein Ausschnitt des Wartungsprozesses duchgespielt werden.
Kundenanruf und Erstellung eines Problem Report
Ein Angestellter eines Kundenunternehmens tritt telefonisch oder per Fax oder Email in Kontakt mit dem First-Level-Support von o.tel.o-Bochum. Ist das Problem alt und bekannt, so wird dem Kunden sofort ein Hinweis zur Problembehebung gegeben und der Vorgang ist abgeschlossen. Andernfalls startet der Mitarbeiter die Aktivität ‘PR Erstellen’ aus dem Wartungsprozeß mit seiner Agenda. Sofort erscheint auf dem Terminal des Support-Mitarbeiters eine Dialogmaske zum Erfassen eines Problemreports (Abbildung 6: Dialogfenster des PTS). Datum und Zeit sowie der aktuelle Bearbeiter sind bereits in die entsprechenden Eingabefelder eingetragen. Das System erkennt den aktuellen Bearbeiter am UNIX-Benutzer, der die Aktivität gestartet hat. Da wir uns im Wartungsprozeß befinden, ist der Problemreport auch schon als extern markiert. Der Mitarbeiter erfragt jetzt vom Kunden alle relevanten Details des Problems wie Problembeschreibung, Installation und Release und trägt sie in die Dialogmaske ein. Bei Betätigen des Buttons ‘Anlegen’ wird automatisch eine neue, eindeutige Problemnummer generiert. Darüber hinaus werden die ersten 70 Zeichen der Problembeschreibung als Kurzbeschreibung erfaßt und der Auftraggeber wird auch als Ansprechpartner eingetragen, falls für dieses Attribut nichts eingegeben wurde. Der Name des aktuellen Bearbeiters wird zusammen mit Zeit und Status an die Historie des Problemreports angehängt. Anschließend wird der neue Problemreport in die Datenbank eingetragen und kann jetzt nur noch durch setzen des Status auf ‘Archiviert’ aus dem System entfernt werden. In der Datenbank bleibt der Problemreport beliebig lange erhalten. Ein Anlegen des PR ist nicht möglich, wenn Mußfelder nicht angegeben wurden. Fehlt ein solcher Eintrag, so wird ein entsprechender Hinweis in der Statuszeile des Fensters ausgegeben.
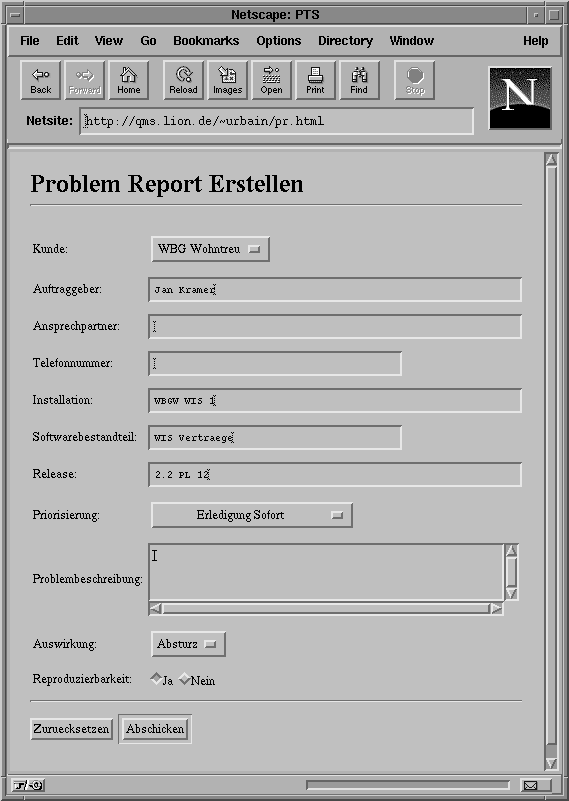
Dem Kunden kann jetzt sofort die Problemnummer mitgeteilt werden. Bei Auswahl eines entsprechenden Menüeintrags wird außerdem ein Kundenbrief mit Kurzbeschreibung und Problemnummer gedruckt, der direkt an den Kunden verschickt werden kann.
Weiterleitung
Zur Weiterleitung eines PR muß sein Status und meist auch sein Bearbeiter geändert werden. Kann der PR alternativ in verschiedene Nachbereichskanäle geschrieben werden, so entscheidet der Status darüber, welcher tatsächlich genommen wird (Abbildung 2: Zustandsübergangsdiagramm). Die Konsistenzprüfungen des PTS erlauben es nicht, den Status und den Mitarbeiter beliebig zu ändern. In der Aktivität PR Bearbeiten kann der Status z.B. nicht zu ‘Aufgenommen’, ‘In Analyse’ oder gar zu ‘Archiviert’ geändert werden.
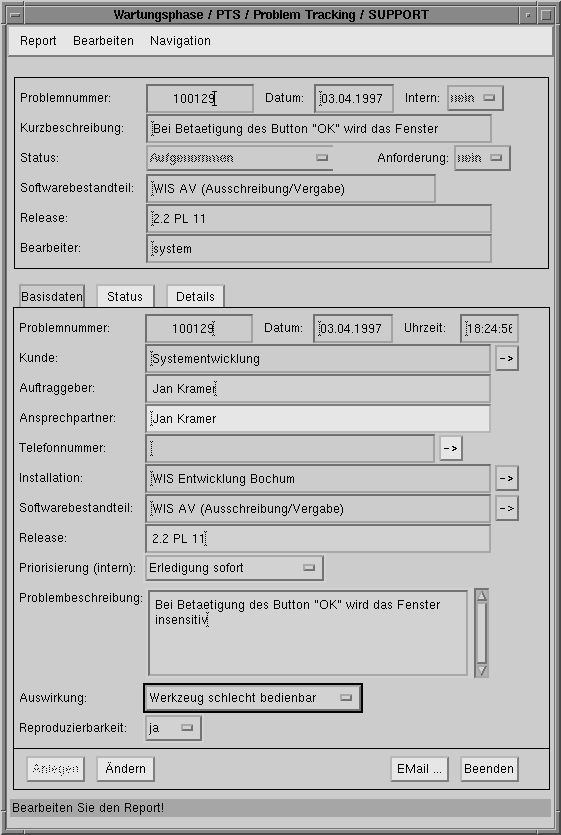
Abbildung 6: Dialogfenster des PTS
Nachdem der Problemreport angelegt wurde hat er den Status ‘Aufgenommen’. Dieser Status kann solange beibehalten werden, bis der Problemreport vollständig ausgefüllt ist und alle notwendigen und bekannten Daten eingetragen wurden. Wird der Status zu ‘In Analyse’ geändert, so erscheint das Dokument im Vorbereich der entsprechenden Aktivität. Diese Instanz ‘PR Analysieren’ ist nur in der Agenda der Support-Mitarbeiter sichtbar und auch nur dann, wenn Problemreports mit einem entsprechenden Status im Vorbereich liegen. Sobald beim Beenden der Dialogmaske der Bearbeiter ein anderer ist als beim Öffnen, wird der neue Bearbeiter per Email über den PR informiert. Das ‘Subject’ einer solchen Email hat die Form
PTS: <Produkt> <Problemreportnummer> <Problemstatus>
so daß der Empfänger der Email schon anhand des Subjects erkennen kann, um welches Produkt es sich handelt, und speziell welche Aktivität er nun zu bedienen hat. Die Email enthält außerdem die Priorisierung, den jeweils letzten Bearbeiter und die Problembeschreibung. Als neuer Bearbeiter kann an dieser Stelle auch eine Gruppe (z.B. Support oder QS) eingetragen werden. Solchen Mitarbeitergruppen sind im PTS ebenfalls Emailadressen zugeordnet, so daß in einem solchen Fall beliebig viele Personen per Email über den Problemreport informiert werden. Dies ist nur sinnvoll, falls innerhalb dieser Gruppen Konventionen darüber bestehen, wer dann für diesen PR zuständig ist.
5 Erfahrungen
Eine Zielsetzung dieses Entwicklungsprojektes wurde offensichtlich sofort erreicht: ist ein Problem Report erst einmal im System, ist die Suche nach ihm beliebig schnell und komfortabel realisierbar. Dazu sind vor allem die vielen Kataloge des PTS hilfreich: Schreibfehler bei der Eingabe eines Moduls, die eine Suche extrem erschweren würden, treten nicht mehr auf. Auch der Bearbeitungsstatus kann allein durch Abfrage des Attributes Status jederzeit ermittelt werden. Die Historisierung des Mitarbeiters zusammen mit Status und Zeit ermöglicht ein Nachvollziehen seines Weges durch den Prozeß und bietet Chancen für Analyse und Verbesserung. Problemreports können aus dem PTS nicht mehr verloren gehen. Früher verlor sich noch jedes neunte Dokument auf den Schreibtischen der Mitarbeiter. Auch jetzt werden Probleme noch doppelt erfaßt. Es ist nun aber sehr viel schneller möglich festzustellen, daß dies der Fall ist.
Insgesamt arbeiten zur Zeit 91 Mitarbeiter mit dem PTS. Zu einem gegebenen Zeitpunkt hat ein Drittel der Benutzer eine laufende Agenda und die Hälfte davon wiederum arbeitet tatsächlich in einer Aktivität. Aktuell werden täglich zwischen 20 und 30 neue Problem Reports erfaßt. Die Aufnahme eines PR mit dem neuen System ist wesentlich einfacher als auf einem Papierformular. Das erklärt, warum seit Einführung des PTS die Anzahl der erfaßten PR pro Tag um einen Faktor von 25% gesteigert werden konnte. Auch gerade Mitarbeiter, die nicht ständig Probleme erfassen, können nun auch zwischen ihrer normalen Tätigkeit Fehler einfacher melden.
6 Auswirkungen auf die Software-Prozeß-Forschung
Der Versuch der Anwendung von Software-Prozeß-Technologie auf industrielle Software-Prozesse hat zu Ergebnissen geführt, die in einzelnen Bereichen zu einer Refokussierung der Forschungsbemühungen führen könnten (zumindest, wenn die Umsetzung dieser Ergebnisse in die industrielle Praxis angestrebt wird). Diese Ergebnisse sind:
Unsere Erfahrungen haben weiterhin gezeigt, daß eine Mischung zwischen detailliert vorgegebenen Modellen und anderen, in denen nur die Rahmenbedingungen spezifiziert werden, innerhalb derer ein Prozeß stattfinden kann, sinnvoll ist, um verschiedene Prozesse und Prozeßteile geeignet zu beschreiben. Genauso wie es zur Erläuterung zweckmäßig ist, die möglichen Zustandsübergange für Problemberichte mit einem Zustandsübergangsdiagramm zu beschreiben, wäre es nützlich, diese Beschreibung auch als Grundlage des Workflow-Managements zu verwenden. Auf diese Weise könnte es möglich werden, einige Teile präskriptiv mit FUNSOFT-Netzen zu beschreiben und die Rahmenbedingungen anderer Prozesse mit Zustandsübergangsdiagrammen zu beschreiben, ohne daß detailliert festgelegt wird, welcher Zustandsübergang wann vorkommt. Die rechnergestützte Durchführung müßte für diese Teile dann nur gewährleisten, daß keine anderen als die spezifizierten Zustandsübergänge auftreten.