FAST: An Integrated Approach to Process Modeling Based on FUNSOFT nets and State Transition Diagrams
| Volker Gruhn | Monika Schneider | Juri Urbainczyk | ||||||||||||
| University of Dortmund | software design & management | Open Software Associates
| Fachbereich Informatik
| Herrnstraße 57
| Ziegelstraße 8
| 44221 Dortmund
| 63065 Offenbach am Main
| 63065 Offenbach am Main
| Germany
| Germany
| Germany
| ++49 231 7279740
| ++49 69 82901-0
| ++49 69 7896 0145
| |
|
Abstract: In this article we discuss the FAST approach to process modeling which combines prescriptive process modeling in terms of FUNSOFT nets and constraint-based modeling in terms of state transition diagrams. FUNSOFT nets are a process modeling language which is used for modeling software processes and business processes for almost a decade. The motivation for the integration of FUNSOFT nets and state transition diagrams is that purely prescriptive models tend to become overly complex. State transition diagrams help to manage this complexity. We show which parts of process models should be described by which language and how parts can be integrated. Our approach is implemented as an extension of a commercially available process modeling and workflow management tool. In addition to the approach and its implementation we discuss our experience in applying the integrated approach to a real-world software process. |
Keywords
software process, process modeling language, FUNSOFT nets, state transition diagrams, workflow management
Various software process modeling languages and business process modeling languages have been discussed in the recent years. Most of them have particular strengths and weaknesses. There is neither a standard nor a de facto standard for process modeling languages. Instead, companies and individual process modelers have their preferences and use process modeling languages which seem most suitable for their particular purposes. The need to combine process modeling languages following different paradigms has been discussed almost ten years ago
[9]. Since then, languages integrating descriptive (or constraint-based) and prescriptive aspects have been demanded from time to time, but no such language has obtained considerable attention, simply because clear integration concepts for both types of process parts and tool support for their integration was not provided.
In the area of non-software business processes, the discussion about the paradigm of process modeling languages is not very controversial. Some process modeling languages are used for communication purposes only. For these languages an intuitive understanding is a first class goal, a precise semantics definition is usually neither available nor missed. Typical examples are event-driven process chains and various data flow languages. Other languages are workflow definition languages. They support the definition of all details needed for workflow purposes [10,11]. Workflow definition languages tend to describe all details about processes which impact the execution of a real process. The typical area of application of workflow management systems are highly structured and routine-based business processes [12]. Most of them are administration business processes which create and manipulate information of only a few classes. Examples are business processes from the area of financial services, business processes of insurance companies and other administrative business process [12]. These processes are described in sufficient detail to allow execution by workflow engines. This kind of execution support is usually called enaction.
In the software process arena the question whether process modeling languages should follow a prescriptive or a descriptive paradigm has determined several European Software Process Workshops [13,14] and some International Software Process Workshops [15,16]. The arguments in favor of descriptive languages are that software developers have their own ways of work and that the software process is not well-understood enough to prescribe it on detail. Instead of that, descriptive process models define certain constraints which have to be respected and they define certain rules of software development, without enforcing any particular order of activities. Based on this idea, rule based languages like the Merlin/ESCAPE language [17] or languages like Oz [18] belong to the most prominent descriptive process modeling languages. Prescriptive languages, like Appl/A [19] or several Petri net based languages like SLANG [20] and FUNSOFT nets [5,21] define in detail which activities have to be executed when and in which order. Their advantage is that deviations of real-world processes from their underlying process models can easily be detected and that software developers are told in detail what to do. Their disadvantage is that this enforcement of processes may hinder creative solutions and individual approaches to certain kinds of problems. Software developers may feel overly controlled and object prescriptions about how to proceed.
Software processes usually contain different parts which deserve special types of process modeling. Certain parts are well-understood and have to be carried out in a precisely defined way. For these parts it is not appropriate to allow for individual solutions which depend on a software developer’s opinion and preferences. Examples are configuration management processes and test processes. For these types of software processes, it should be avoided that software developers define what to do when, but it should be enforced that certain activities are carried out in a certain order. Anything else should be avoided by all means. For other parts of software processes detailed models cannot be provided. An example is a process for the modification of a design. Perhaps it is not necessary to describe in which order and by means of which tools interfaces of components and modules are modified, but we want to ensure that certain results are obtained and that certain levels of consistency are not violated during the modification. For other processes, we have to admit that they are ill-understood, such that it is simply impossible to prescribe in detail what has to be done, This applies, for example, to requirements elicitation processes. Experienced software developers have their own ways for doing so and we want to exploit this knowledge. We do not want to overburden requirements processes by overly detailed descriptions about how to specify requirements, which tools to used or other details. Another example is a cost estimation process which – despite all the sophisticated cost models available – still depends on the experience of senior project managers. We consider it useless, even harmful, to waste this experience by prescribing that certain parameters have to be identified in certain ways and to derive the cost estimate by some obscure algorithms processing these parameters.
Summing this up, we believe that there is sufficient reason for process modeling languages following different language paradigms. In order to obtain process models reflecting that different process model parts deserve different levels of detail, software process modeling requires to combine modeling paradigms. This is what we implement in the FAST (FUNSOFT nets And State Transition Diagrams) approach presented in this article. The basic idea of our approach is to integrate a constraint-based approach to process modeling into an otherwise prescriptive process modeling language based on FUNSOFT nets [21].
The structure of this article is as follows: In section 2 we introduce a software process example which shows how to manage problem reports for a complex software product. Key parts of this software process are described in terms of FUNSOFT nets. We use this example to briefly introduce the notion of FUNSOFT nets. We also discuss the problems of using FUNSOFT nets for modeling ill-understood parts of software processes. Then, in section 3, we introduce the idea of the FAST approach, namely the specification of constraints in terms of state transition diagrams. Section 4 sketches how modeling in terms of state transition diagrams could be integrated into prescriptive modeling in terms of FUNSOFT nets. Details about the interfaces between FUNSOFT nets and state transition diagrams are discussed in section 5. Section 6 illustrates the enaction semantics for process models formulated as FUNSOFT nets and state transition diagrams. Section 7 describes our experience in using the FAST approach for modeling real world process. Finally, we conclude with a discussion of our future research work.
FUNSOFT nets are high level Petri nets, which have been introduced into the software process modeling community some ten years ago. They build the basis of the commercial workflow management tool LEU [12] and the process modeling tool Leu smart (http://www.adesso-gmbh.de). The FUNSOFT net approach is to model processes in terms of:
Activity models and organizational models are integrated by defining which role is responsible for which activities. Activity models and object models are integrated by defining the classes of results and inputs of activities. Rectangular symbols of activity models (compare figure 1) represent activities, they are called agencies. Different symbols are used to denote different kinds of agencies (like agencies which are refined, which can be executed automatically, which demand for human interaction, etc.). Agencies are implemented by a piece of code attached to them. In workflow management, this piece of code is executed, when an agency is fired. Circles represent information in certain states, they are called channels. Each channel is associated with a class from the object model. During workflow management, each channel can only store objects of the associated class. Edges between agencies and channels represent data and control flow. The semantics of FUNSOFT nets are defined in term of Predicate/Transition nets. This semantics definition is based on a local unfolding from FUNSOFT net elements onto Predicate/Transition nets [22]. In the following example we restrict ourselves to activity models.
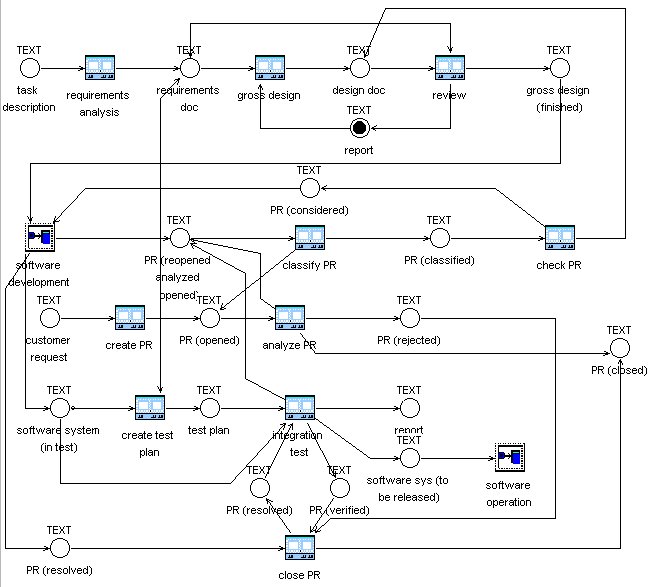
Figure 1 : Software process model
Software Process Example: Management of Problem Reports
Figure 1 shows a FUNSOFT net which depicts the activity model of a software process which covers requirements analysis, gross design, management of problem reports (PR) and some parts of software testing. Certain activities (like software development and software operation) are described in more detail on a lower level. Agencies representing these activities are denoted by special symbols, which indicate that details are defined by an agency refinement [23].
Figure 1 shows some agencies which represent requirements analysis and design activities (top part), several agencies centered around problem reports and their management (central part) and a few agencies which represent the core of software development (called software development, create test plan and software operation). The example shows that the management of problem reports is a rather complicated business. Problem reports may change their state according to some rules defined in terms of activities which read and write problem reports. The activity to analyze a problem report (represented by agency analyze PR), implements the rule that an opened problem report is either rejected that it is considered to be fixed or that it is closed. The channels representing these three states appear as output channels of agency analyze PR. The detailed rule which output channel is marked in analyzing a problem report is hidden as implementation of agency analyze PR. The behavior to produce only one output object while three channels are connected as output channels is one of the extensions of Petri nets implemented by FUNSOFT nets. It is a deterministic output firing behavior. Other firing behaviors of agencies are defined as standard FUNSOFT net firing behaviors. These predefined firing behaviors as well as some access strategies to channels (as queue, as stack or random) are FUNSOFT net features, which cannot be found in standard Petri nets. The semantics of these features are defined in terms of standard Petri nets. Our experience is that these features help to communicate FUNSOFT net activity models with process owners. They contribute to process models which match with the intuition of process people and ensure that people who use FUNSOFT nets for process modeling do not need detailed knowledge about Petri nets. Details about FUNSOFT nets can be found in [21]. Details about how to manage problem reports can be found in [7].
Experiences with Activity Modeling
Figure 1 has been chosen intentionally to illustrate one major drawback of FUNSOFT nets in particular and prescriptive process modeling languages in general. This drawback is that the immediate need to prescribe in detail which state transitions are allowed leads to models which are over-burdened by technical details about specific state transitions. These details detract from the overall structure and purpose of an activity model.
The software process described in figure 1, for example, shows that it is very difficult to determine what happens to problem reports. Even though the figure only shows a part of a simplified version of a software process there are seven agencies reading, manipulating and writing problem reports and nine channels typed with the class "PR". We visualized the states of problem reports created by agencies by adding these possible states to the class attached to channels. All these channels and agencies are needed for rather obvious and easy to understand state transitions which define the dynamic behavior of problem reports. Beyond what is expressed in the graphical representation of the activity model, it has to be described in detail, which successor states can be reached and under which conditions these states are reached. Details about these rules for state transitions are given as implementations of the activities, they are not included in figure 1.
If we want to grasp the idea of the overall software process then this seems overly sophisticated on the first glance. The prescriptive nature of activity models expressed in Petri net like formalism demands to fix input and output relationships in detail. We experienced this prescriptive approach as hindering whenever parts of process models deal with objects of only one class (as the central part of figure 1 which shows all activities centered around problem reports). Here we have to enable many alternative state transitions. Which one is actually chosen depends on the knowledge of the user.
For explaining these parts it appears more intuitive to describe all potential state transitions without defining in detail which activities implement which state transitions immediately. In other words, the first step could be to define the state transitions in a descriptive way (thus, fixing which state transitions are allowed in principle, but not defining in detail which state transitions are allowed in which order). This opens the path to the integration of a constraint-based specification of process parts into otherwise prescriptive process models. In this integrated approach, constraints are formulated in terms of state transition diagrams which are considered as integral parts of object models. The potential state transitions for objects of one class are considered as part of the definition of this class. When, for example, the class "PR" is defined, then the dynamic behavior of this class should be defined as well as its static aspects (attribute names, attribute domains).
The overall perspective of our approach is still process-oriented. Processes to be modeled remain in the focus of our modeling efforts. Only certain parts which cover aspects related to only one class and which are determined by a set of potential state transitions are modeled in a constraint-based way (compare STD agency PR management in figure 2). They are integrated into prescriptive activity models formulated as FUNSOFT nets.
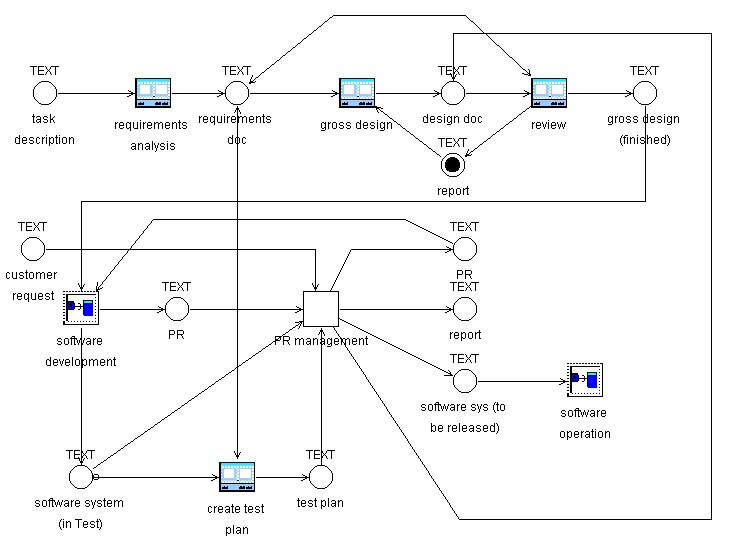
Figure 2 : Software process model with STD agency
In order to describe the changes of an object over time we introduce the state transition diagram (STD or statechart). In business processes the user is usually responsible for manipulating the objects. The objects do not act on their own behalf but only change as a result of direct interaction with the user. This interaction leads to a change of the attributes of the object, thus changing its state. The STD shows the possible states of the object and the transitions from one state to another which can occur during the objects life cycle.
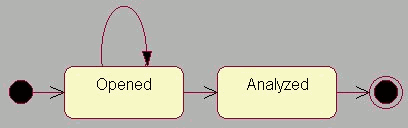
Figure 3 : Example for a simple STD
We adopted the way of modeling our STDs from the Unified Modeling Language (UML) [1,6]. As can be seen in Figure 3, states appear as rounded boxes containing the names. Transitions from one state to another are depicted by an arrow connecting the two states. The arrow may be accompanied by the name of the action which causes this transition. A second form of transition is the cycle, which starts and ends at the same state. This is illustrated by an arc-shaped arrow which connects the state with itself (see the cycle from ‘Opened’ to ‘Opened’ in Figure 3).
There can be multiple transitions leading to as well as away from a state. This is a means of modeling alternative paths in the life cycle of an object. In our STD there must be at least one transition leading to every state. All states in which an object can be created (create states) must be connected to black dot by an arrow. Figure 3 shows an STD with the state, 'Opened' which is a create state. All states in which an object may be destroyed (destroy states) must be connected to a circled black dot. The UML allows for super-states which include other states, but currently we don’t support this feature. Likewise, we don’t yet have a hierarchy of STDs and there are not sub-STDs like in SOCCA [2,3].
We find the possible states of a class by using the following method: we think of a state as a collection of values for a given set of attributes. Therefore, every reasonable combination of values defines a separate state. For each state we specify which attributes are mandatory and we define that the values of some attributes must contain certain values or satisfy certain conditions (such as, the attribute ‘Priority’ must have a value between ‘1’ and ‘3’). Internally, we build up a state definition table which holds all the data on the states of the respective STD. Thus, we can exactly determine if an object is in a certain state or not. This only depends on the values of its attributes at the time we look at it. For example, a problem report stays in the state ‘Opened’ as long as the attribute ‘Priority’ is empty and the attribute ‘Analyzed by’ has not been set. One of the many free attributes, which do not contribute to the definition of the current state, is ‘Responsible’ which holds the name of the person currently in charge. The state of the object is not influenced when this free attribute changes its value. Likewise, the value of this attribute is independent of the state of the object. It is important to note that the definition of each state has to be orthogonal. It must always be possible to conclude about the objects state only from looking at its attributes. E.g., the definition of one state must not be a subset of the definition of another state. This way of defining the state is formal and can be used as basis for enactment.
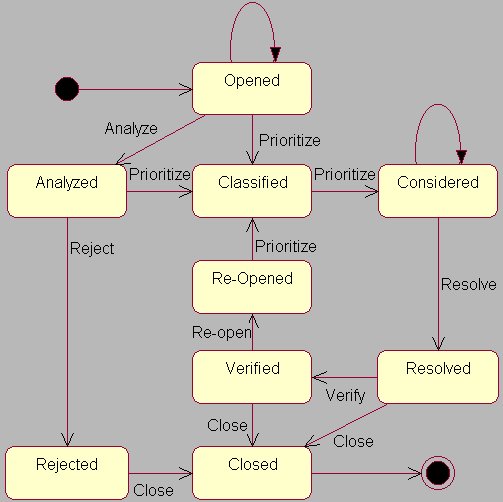
Figure 4 : STD for the class 'Problem Report'
State transition diagrams are a part of the object modeling. The number of states in the whole software system increases rapidly with the size of the system. This normally leads to huge number of states which cannot be handled anymore. Therefore, we try to battle this ‚state explosion problem‘ by focusing on the classes and building statecharts for each class separately. We found that the number of states in a single class usually is not larger than 20 provided that the object models are well structured and that our method of state finding is applied.
In the object modeling we design the class hierarchy of the system and the dependencies of the classes. For each class we define its attributes and its methods. Additionally, we can build up the STD for this class. This STD contains the names of all possible states, the transitions connecting them and the names of the action for each transition. The actions are important, because they are proposed to the end user as possible operations in his agenda. During runtime each action is represented by a dialog (see section 6).
Now, the states must be defined using the attributes of the class, which can be done in the separate state editor. This editor shows all the attributes and inherited attributes of the class. For each attribute we can define if it is mandatory for this state and which values for the attribute are allowed in this state. For a create state the value of every attribute must be specified. Furthermore, we define whether an attribute is editable and whether it is visible in this state, which is important for enactment (see section 6). For example, the attribute ‚Priority‘ is only editable in the states ‚Opened‘ and 'Analyzed' (see Figure 5).
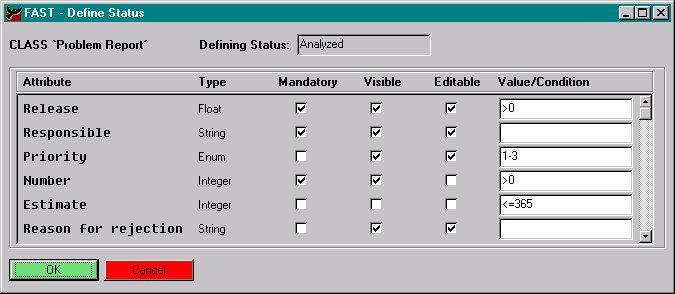
Figure 5 : State definition on attribute level
Since the STD is used as a basis for execution it has to be absolutely consistent with the semantics of enactment. To that end, the user can start a consistency check on the STD, whenever he regards the modeling as completed. This consistency check has to make sure that the following conditions apply:
When the definition of the states and the STD itself is complete, it can be connected to other parts of the system. Above all, we want to use the attribute definition of the class for an automated dialog generation. We assume that the graphical user interface (GUI) for editing the objects does not need to be replaced during the objects lifecycle. Therefore, the GUI for each class stays more or less the same during enactment and it can be generated from the class description. Of course, we can also utilize the fact that we know which attributes can be edited in a certain state. Thus, the appearance of the GUI can be modified corresponding to the definition in the object modeling. This is done by switching visibility or sensivity of certain GUI elements. The dialog generation creates a panel for each class. All possible attributes, depending on the current conditions, can be edited in the panel. This gives us much greater flexibility in designing the dialog windows for the end user. E.g., it enables us to place one of these panels together with additional elements in one and the same window. There can be even two or more panels of the same class in one window, one of them for editing and the other just for viewing an object. Moreover, it is possible to edit more than one object of the same class at a time, which is subject of future research (see section 8).
The STD modeling can also be linked to the role model. Most business processes are based on sharing responsibilities between multiple actors. In FAST this is expressed by modeling roles in the permission system and by assigning certain roles to different users. In the object modeling we can create a state versus role matrix [4], thus defining which state may be accessed by whom. This matrix is evaluated during runtime and governs the distribution of actions in the agenda system.
The creation of a statechart is optional and is needed only if you want to utilize the STD feature for a given class. E.g., we don’t draw a statechart for the class ‘task description’ in the process of Figure 1. Since it is difficult to model behavior which involves objects of different classes with statecharts we recommend to only draw an STD for those classes which have limited interaction with other classes. This is not a major drawback, since complex interaction can still be modeled using FUNSOFT nets (see section 2).
As an example we simplify the software process shown in Figure 1. There are seven agencies manipulating problem reports, i.e. ‘classify PR’, ‘check PR’, ‘create PR’, ‘analyze PR’, ‘close PR’, ‘software development’ and ‘integration test’. Six of them deal mainly with problem reports. Therefore, we replace them with one STD agency and an STD for the class ‘problem report’. The preset of all six agencies consists of channels typed with ‘problem report’ (six times), ‘customer request’, ‘software system’ and ‘test plan’. That means the preset of the STD agency must consist of four channels: three are typed with ‘customer request’, ‘software system’ and ‘test plan’ and only one further channel is needed for the problem report. In the same way, the postset of the STD agency consists of four channels typed with ‘problem report’ (of which we had eleven before), ‘report’, ‘software system’ and ‘design doc’. The new version of the activity model is shown in Figure 2.
Now, the STD agency must be specified. As with all other agencies in the activity model it has a name, a preset, a postset and a firing behavior (see section 2). Additionally, the following must be defined:
Figure 6 shows a dialog in which these properties can be specified. Simple information like name, time and firing behavior can be defined using edittexts. The first three of the new items (STD, preset channel, postset channel) can easily be specified by selecting them from a list of STDs and channels. If the postset does not contain a channel typed with the class of the STD no channel can be marked to read an object from. This means, the object does not yet exist and must be created when the agency is enacted (see section 6). In the same way, the object must be destroyed at the end of the enactment if there is no channel for it in the postset. For defining when the enactment should stop the statechart is used. In the statechart a number of states can be marked for the current STD agency. These states are called stop states. Defining these stop states is important for the enactment of the process containing the STD agency. Whenever an object reaches such a state the enactment of the STD agency is terminated and the object remains in its current state even when there are following states. A stop state can be located anywhere in the STD. And it can be marked for more than one STD agency, because each mark only is responsible for stopping the enactment of a certain STD.
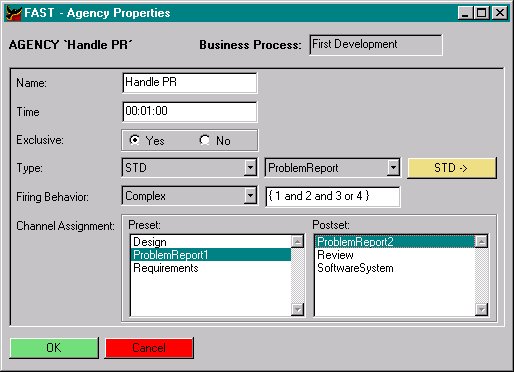
Figure 6 : Properties dialog for an STD agency
After the activity modeling is finished the user can run a consistency check. This check is now extended by tests concerning the new STD agency. Some of them are:
Finally, when doing these tests, the system automatically marks all states with no successor as stop states. Because no further actions are available when an object is in one of these states, the enactment of the STD agency must stop there.
When we first came up with statecharts in the context of a process modeling project, it was only meant to enhance our design and documentation papers. As we continued to define states on attribute level we realized that this could as well be the basis for enacting the so-described classes. The current implementation allows for distributing the enactment between process-focused and state-focused (data-centered) parts. As a whole, the enactment is process-driven. The activity model which represents the process is interpreted by the so-called process engine. Whenever an activity fires a certain part of the system is responsible for executing the feature connected with the activity. What part of the system is triggered depends on the agency’s type. E.g., if the agency is bound to a function, the function interpreter is launched. If the agency is bound to another activity model, another process engine is activated. If the agency’s type is ‘dialog’, the dialog interpreter assumes control. As a fourth type of agency, it can also be bound to an STD (see Figure 6). In this case a state engine is started. Nonetheless, in all of these cases the process engine keeps running and continues to work separately from the newly started engine.
The state engine constitutes a separate thread for every agency which fires. If the same STD agency fires twice in sequence, two separate entities of the state engine are created. This is possible since the process engine guarantees the uniqueness of objects in the workflow. The state engine is responsible for enacting the statechart for one object of the firing activity’s class at a time. Furthermore, the state engine has to communicate with the permission and role system, with the dialog interpreter and with the agenda system of the users (see Figure 7). It is important to note that the state engine is insulated from the rest of the activity model currently executed. Other activities can fire while the state engine is working and there is no interference with other tokens in the FUNSOFT net.
When the state engine is started, the process engine passes information about the class and, implicitly, about the statechart it has to enact. It also needs to know the exact object which shall be enacted If there are tokens in the preset of the STD agency they are converted into objects and also handed to the state engine. It is possible that there are no objects of the class to be STD-executed which could be passed from the process to the state engine. This causes the state engine to create a new object of its class and to put it in its respective create state. Thus, the default values of the newly created object are well defined. This is the reason why every statechart must have one create state. Otherwise we could not guarantee the existence of an object for the state engine.
There are two different startup modes for the state engine: either it gets the tokens passed on from the process engine and creates objects from them or it has to create the object from scratch. Either way, after initialization is done there is one single object it is responsible for. Now the state engine executes the following steps repeatedly:
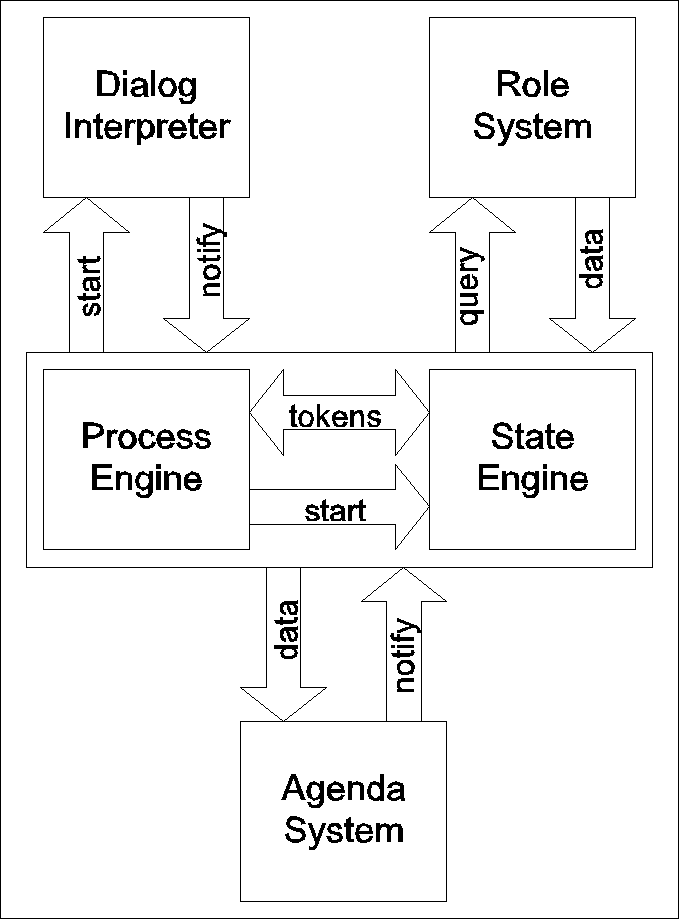
Figure 7 : FAST process architecture
It is important to note that there may be STDs which have no stop state and no destroy state. Once started, state engines enacting those STDs would run as long as the whole workflow environment is in operation.
As discussed in section 2 the FAST approach works best when applied to a 'mixed' process which consists of clearly structured as well as poorly defined parts. This is the case with most software processes since they contain very different types of work in heterogeneous environments. Eventually, we had the chance to use FAST for modeling and enacting the development process for primary and prototype releases. This project started in a middle-sized international software company which is focused on the tools market. Furthermore, we had the possibility to compare this project with a similar one in a German telecommunications company [7]. This project was done without FAST, just using the conventional workflow modeling environment LEU.
At first sight we thought that the amount of analysis and design work would be increased when working with FAST, since there is extra effort necessary to insulate the respective classes for STD-modeling and to find the appropriate agencies to merge into one STD agency. On the other hand we learned that thorough analysis had to be done, even when working with conventional techniques. Nevertheless it is true that there is some additional effort when constructing the STDs and, above all, when defining the state on attribute level. But this seems to be rather a shift of work from the coding phase into the design phase. A lot of implementation can be omitted due to the fact that it is implicitly done during design. Even more important is that the consistency of the data for the STD-enacted classes is guaranteed by the system itself. This is largely due to the sophisticated validation logic of FAST which can be automatically generated from the state definition. With conventional modeling consistency is endangered since it is easy to forget some parts of the necessary code.
We saved a lot of time in the new project during dialog modeling. There was no need for manually modeled dialogs, so we could intensively use the generated panels. Since these panels can be modified automatically, regarding the current state of the object, there was hardly any extra any work in the GUI. This lead to another very positive experience. Since we do not need a lot of individual implementation, the reaction to change requests and the resolution of errors was much easier than in the project before. E.g., a bug in the dialog implementation, on average took us only half an hour to fix, instead of 6 hours in the earlier project. This is largely due to the fact that there is only one location where we have to apply changes in order to have the error removed from all dialogs. Most frequently error occur in object modeling, which can be removed very easily in FAST.
Furthermore, FAST makes it easier to accept requirements changes during coding phase. In the conventional project it happened that the actual process of the workflow was changed when the system was nearly ready. This gave us a hard time, since we had to change the workflow and to modify all implementation which was connected to the new channels and agencies. In doing so we delayed the project for two weeks. A similar change request in the FAST project just lead to a further state to come into existence which left the workflow model totally intact. The change to the STD and the definition of the new state was completed within three days.
The integration of FUNSOFT nets and STDs was the first step for supporting a better view and therefore a better understanding of each part of a process. In the former sections some possible extensions to this approach have already been mentioned and some more are presented in this section.
We want to allow for interaction between STDs. Currently, the transition of an object from one state to another can only be triggered by actions defined within it’s own STD. The next step is the possibility to involve actions of other STDs with the transition of an object. Then, an object might only be able to change its state if another object triggers a certain action by reaching a certain state. The type of the second STD is not important in this case. An object might wait for another object of the same class as well as for an object of a different class. This mechanism could support synchronization between objects similar to interaction diagrams.
Another topic is to allow a single STD agency to deal with more than one class. For example, the software process shown in Figure 1 and Figure 2 is extended by a maintenance part. In this part a class called patch is introduced. A patch consists of a number of system changes caused by problem reports. Thus, it may be useful to define an STD for patches and bind it to an STD agency which creates and defines patches and additionally marks problem reports as solved by these patches. This STD agency has to manage two STDs: problem report and patch.
Furthermore, we plan to build a monitoring tool similar to the one we use for activity models. With this tool it should be possible to see which STDs are currently interpreted and in which states the objects are. Then, for example, an administrator can find out why the enactment of a process has stopped while executing an STD agency and what must be done to go on.
Given that existing activity models should be modified by using the new STD agencies there should be some assistance for the user. Therefore, we want to build a mechanism which supports the user in changing the model. The user only has to mark all agencies he wants to replace by an STD agency and the replacement is done automatically. All superfluous channels and edges are deleted and the necessary new connections are made.
An important topic is to think about process evolution. Business and software processes change over time. Therefore, our system already has a mechanism for supporting changes of activity models [4]. Now we have to support changes of the STDs as well.
When dealing with classes and STDs an obvious task is to think about inheritance. Therefore we want to extend our approach by allowing for STD inheritance. In this context we partially can adopt the inheritance mechanism of our object modeling. Then, we have to define how the state engine works with inherited STDs.
Last but not least, integrating STDs with FUNSOFT nets was the first and most obvious step. Other modeling techniques like interaction diagrams can follow.
REFERENCES